High Availability Web Server Caching with Redis
 Over the past few weeks, I’ve had the privilege of re-architecting the fonts.com web server caching strategy. The design isn’t anything groundbreaking, but it was still fun to build and worth sharing.
Over the past few weeks, I’ve had the privilege of re-architecting the fonts.com web server caching strategy. The design isn’t anything groundbreaking, but it was still fun to build and worth sharing.
Architecture Diagram
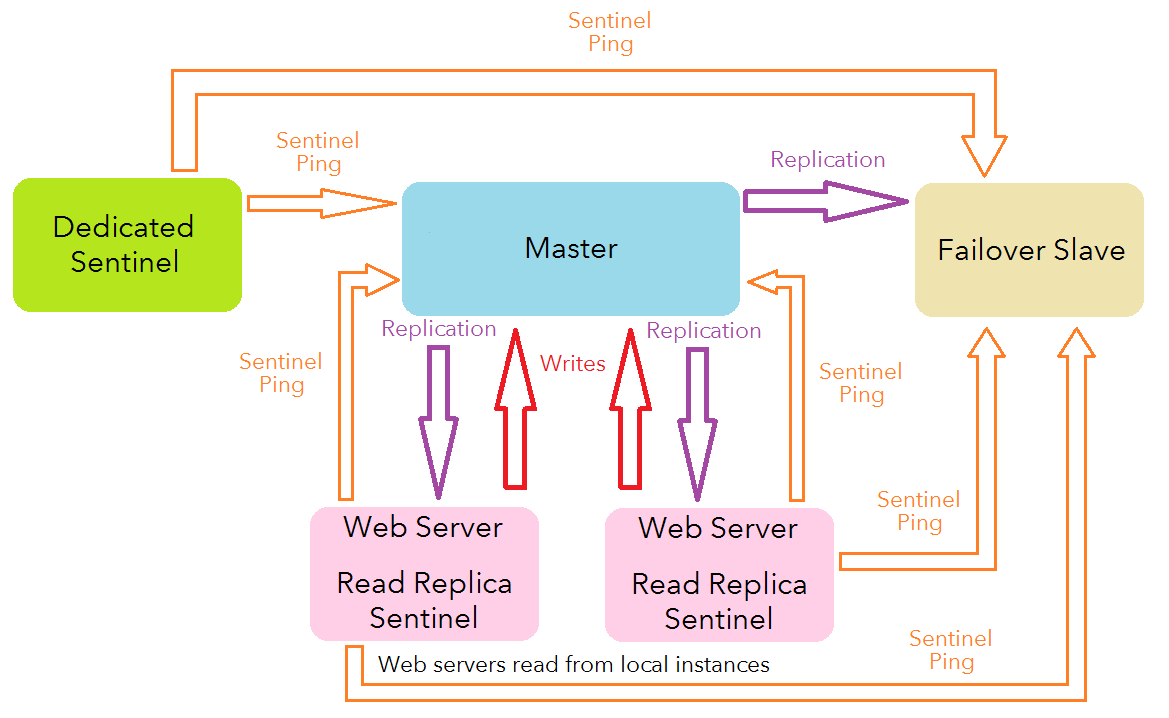
Breakdown
There are a few ideas at play here:
Local Reads
Fonts.com typically requires two front-end web servers to meet demand(8 cores, 16 GB of RAM each). At our scale, it is within reason to have the master instance replicate to the two online web servers and the failover slave. The web servers are configured to attempt to read data from the local Redis instance before falling back to a more expensive source. The result is then serialized to JSON and written as a normal string value to the current master instance. If the requested key is available locally, a network hop is saved. This strategy also eliminates the need for a potentially complicated cache invalidation mechanism; the same data will be replicated to each web server after any writes or deletes and keys with TTLs will expire at the same time.
Redis Sentinel
Redis Sentinel is a tool bundled with Redis that can help with monitoring and failover. It will periodically send pings to the current master to ensure it is still reachable. It also can automatically detect slaves and other Sentinels in the system (OK, so I left out some arrows from my diagram above). In the event a master becomes unreachable according to a Sentinel, it will communicate with other Sentinels to determine if a new master should be elected. If the (configurable) number of Sentinels agree that the master is down and a quorum is reached, a new master is elected and the web servers are informed they have a new destination for writes. By definition, quorum needs to be at least 51% consensus. In the event the master goes down, a quorum would be impossible with only the two web servers, so an additional Sentinel was configured on a stand-alone machine so quorum can be reached.
Slave Priority
It would be undesirable to allow the Sentinels to elect one of the read replicas running on the web servers as the new master during a failover. Luckily, the Redis instances themselves can be configured with a “Slave Priority”. By setting a higher slave priority on the designated failover slave, the Sentinels will elect it as the new master during a failover. A value of “0” for slave-priority means that slave can never be elected master.
Disable Persistence
For a web server cache, on-disk persistence isn’t really neccesary. Disable it by commenting out or removing the “save” lines and setting “appendonly” to “no” in redis.conf. (save examples are from the default redis.conf)
Advantages
The most obvious advantage to this design is a local copy of shared data. Some of our cached objects can be somewhat large (Font data can be surprisingly complex. No, really). Retrieving from memory locally can be a nice time save.
Another advantage is that system-wide cache invalidation is trivial and the system is only a few milliseconds away from being in a consistent state after writes (barring network partitions of course, but that’s what we get for favoring an AP system).
Drawbacks
One major drawback of this approach occurs during a failover. When Redis slaves change masters, every key is wiped from the database and the slave begins to sync with its new master from scratch. The new master will need to replicate to the read replicas on the web servers, which means it may be a potentially long time before we can start serving from cache again.
Another drawback is scalability. Adding more web servers to meet an increased demand means more replication from the master. Logic dictates there will also be more writes to the master with increased traffic to replicate. A different approach would likely be necessary under heavier load.
Finally, the additional overhead of both a standalone Sentinel instance and an unused read replica can be considered a waste of resources for such a rare occurrence.
Conclusions
Like everything in engineering, this design is a series of trade-offs. Overall, I’m happy with this approach and I’m confident it will produce great results in the near future. Time will tell if I’m right or not!